Everything we interact and work on, creates data in the digital world. Whatever interactions we do in the computer world will leave data as the footprint. All the files, images, audio/video files that daily we watch and use are nothing but data. End of the day we are left out with little bright “gleam” on data that we are exposed to. We are now in the pinnacle era of data access. It would be a better idea to understand data storage concepts and technologies.

All this data will be obviously in the form for 1’s and 0’s which is nothing but binary data. This data needs to be stored somewhere and some form to access it later. This data could be needed for processing or to come-up with any insights later.
Storing data is very crucial and has led to development of many technologies. During late 1970’s and beginning of 1980’s storage saw emergence of new technologies and many developments happened during this period.
Table of Contents
Storage Concepts
Data can be stored in many formats in any computer hardware. This completely depends on the application that is creating this data. Following are some of the well-known data storage formats and access mechanisms.
Disk Storage
Many of the disk operations like “read” and “write” involve disk storage.
Disk storage is one of the most heavily used mechanisms as on today. In Disk storage, also many types and methods have evolved over a period.
- Block Storage: Data is stored in “logical blocks” these blocks are smallest units of storage with addresses attached to them in any storage subsystem. Disk level read/write operations can be used for block storage and block storage access.
- File Storage: Any data file is nothing but collection of “block of blocks” of data. Any file typically will contain two parts:
- Meta data of a file which stores the directory structure and information about the file.
- File content which contains the actual file content part of the data. File storage leads to File Systems, which will have directories, files, regular files and etc file related meta data inside them. These File Systems are logically arranged for ease of access and data operation.
Database Storage
DB storage is data storage for faster access with or without data relation. DB storage is at the software level of data storage and will involve SQL or No-SQL based data storage with Primary key and secondary key mechanisms. These data bases either will be relational and no-relational types. The scope in this article will not cover these concepts.
Secondary Storage
This mainly involves hard disk type of storage. As explained earlier, for last 20+ years or so, storage was hovering around DASD (Direct Attached Storage Device) or JBOD (Just Bunch Of Disks) types of primary storage mechanisms. DASD and JBOD were used for just read and write operations on disks. These are just collection of disks without involvement of data management or intelligence used.
- Disk: Disk is one of the storage units used for data storage.
Primary Storage
It is also known as main storage mechanism will mainly involves Random Access Memory.
- RAM
- ROM
- EEPROM
Storage Technologies
1. RAID (Redundant Array of Independent Disks)
RAID technology was developed keeping in mind the need of back up, faster data access and error free data with availability features. RAID was developed using combination of multiple independent hard disk drives into a single logical unit. The underlying Operating System sees all these as one single HDD (Hard Disk drive). RAID also provides with fault tolerance.
RAID has multiple features and techniques, which were developed over a period. These have been developed based on back-up, recovery and data distribution in the hard disk drive. I have explained some of the required and well-known features as below.
- Read and Write policy: Normal read and read ahead policies with write through and write back.
- Consistency check: This operation helps in verification of correctness of data in the virtual drives that uses the RAID levels 1, 5, 6, 10, 50, 60 and except RAID 0.
- Hot Spare disk: This is a stand-by drive, which is in idle state, powered-on state can be used immediately in case of any drive failures in the RAID group. This disk generally will not have any user data.
- RAID level: To deliver higher data availability, performance and redundancy of stored data, set of techniques are applied to group of disks.
Types of RAID
RAID is also classified as Software RAID and Hardware RAID.
Software RAID:
- RAID calculations are handled by underlying OS or by system CPU.
- Slow response and low speed due to overhead of calculations.
- Many OS boot will fail or struggle to boot due to system mirror failures or due to some software failures.
- Not immune from virus attacks.
Hardware RAID:
- Card will be handling the RAID calculations.
- Improved speed as only XOR operations are done.
- Recovery from disk failure is easy.
- Immune to virus attacks.
RAID Levels
Over a period, several RAID levels have been developed and some of the popular are:
- RAID 0
- RAID 1
- RAID 1E
- RAID 5
- RAID 5EE
- RAID 6
- RAID 10
Note: Out of these RAID, only important and most used configurations are described here with more details.
RAID 0 (Data Striping)
- RAID 0 spreads data across several drives for speed.
- This uses block level striping for data distribution. Provides high rate of read and write performance.
- There is no data redundancy in RAID 0 configuration.
- No fault tolerance is used here.
- RAID 0 needs minimum of 2 disks.
")
If any disk fails, all the data is lost. No fault tolerance.

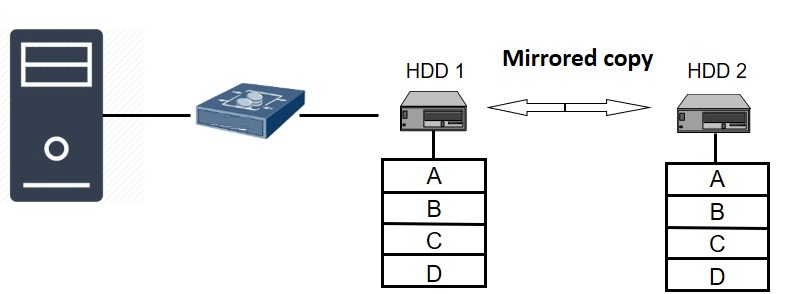
RAID 1 (Data Mirroring)
- RAID 1 is used for Data mirroring operation.
- All the copies of the data is written on both the disk drives for redundancy.
- No striping is used here for data distribution.
- This configuration requires minimum and maximum of 2 disk drives.
- Here 50% capacity loss happens and 100% redundancy.
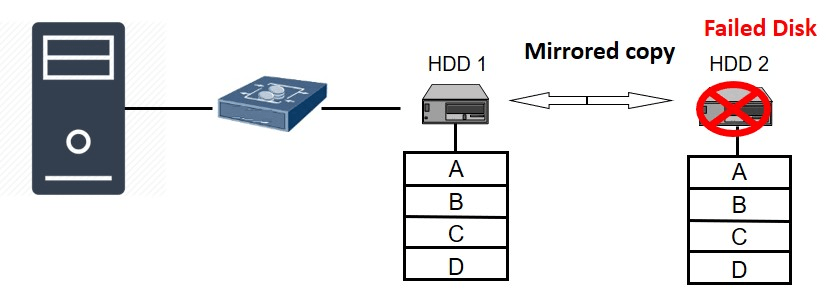
If one of the disk drive fails, the data is available with other copy.
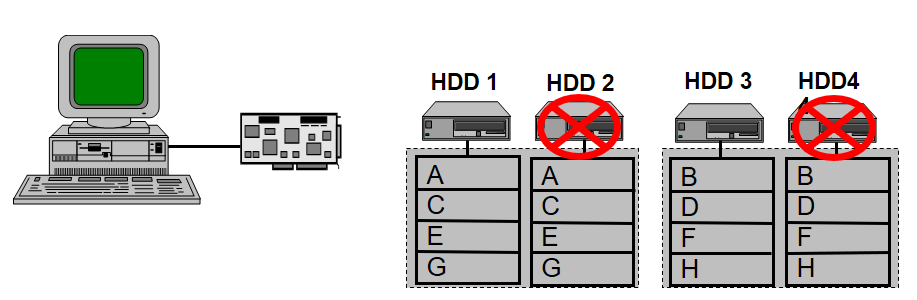
RAID 10 (Striped array of Mirrored disks)
This configuration will help in disk failure in both mirror sets. The following are some of the features of RAID 10.
- Provides high I/O rates due to multiple striped segments.
- Minimum of 4 drives are required for this configuration.
- 50% capacity will only be available.
- Gives good write performance.
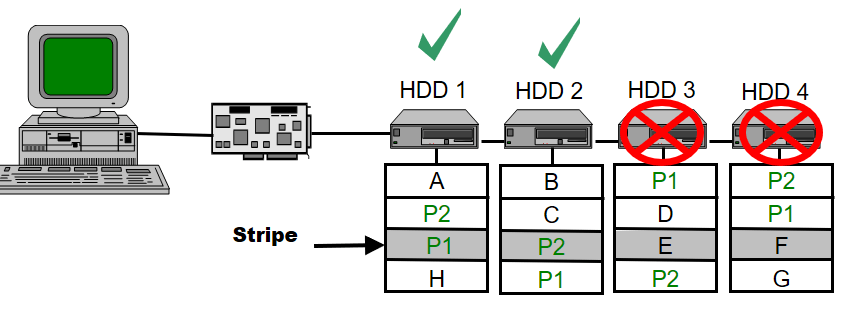
This configuration supports up to 2 disk failures
Note: Parity is a calculated value used to reconstruct data after a failure. While data is being written to a RAID-5 volume, parity is calculated by doing an exclusive OR (XOR) operation on the data. The resulting parity is then written to the volume. This helps in distribution of data across disks.
RAID 5 (Striping with distributed parity)
- This configuration stripes data in block level and distributes the parity across the members of hard drives of RAID group for data protection and availability.
- Parity is calculated using XOR operation.
- Uses block level striping and uses distributed parity.
- 100% redundancy.
- Provides better use of capacity as compared to RAID 1.

RAID 6 (Striping with dual distributed parity)
This again uses block-level striping with dual distributed parity.
- Here two independent distributed parity schemes are used.
- Main purpose of this is for fault tolerance.
- This can handle any two drive failures in this whole array.
- Requires at least N+2 drives for implementation of this configuration.
No data is lost even if two disk failure happens in this configuration as parity is also distributed.
2. DAS (Direct attached storage)
Here, collection of disks, which are directly attached to Host. This is low cost model, easy to use and connect mechanism. Simple connection used here, either by using FCS (Fiber Channel) or by SCSI cabling. In some cases, HBA (Host Bus Adapter) is used along with SAS (Serial Attached Storage) also. This mechanism is not reliable and is not an efficient way to use. This mechanism is used in some cases for low cost & non-reliable models.
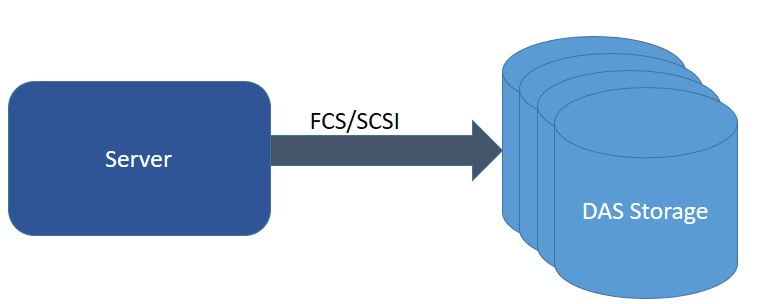
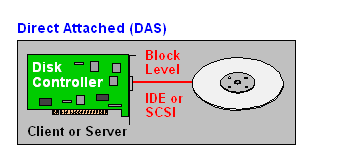
3. SAN (Storage Area Network)
This technology is based on the concept of “Block level input/output” with high speed. This mechanism is very efficient, secure and reliable. This mechanism is little bit expensive as this involves lot of hardware components for connectivity, controller machines and adapters. In addition, various protocols like iSCSI, SCSI, FC, FcOE are supported and this needs some intelligence in connecting.
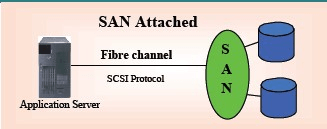
The above diagram is that of a simple SAN connection. As explained earlier this has been connected either using FC or iSCSI based protocols. SAN is nothing but a simple DAS, which adds all of its storage in the network and provides block oriented data access between the target storage on network and the computer system. SAN uses high speed, dedicated FC (fiber channel) network or iSCSI (which is nothing but Ethernet).
SAN has many advantages as listed below:
- Access to SAN can be over longer distances up to around 10-100 kilometers and with high-availability.
- SAN provides us with improved performance.
- Provides protection and data back-up over LAN network.
- Provides data sharing with security and reliable network connectivity
SAN has disadvantages as well.
- SAN configuration is very expensive as this involves multiple components.
- SAN configuration is complex and challenging.
- Maintenance of SAN needs greater skills.

The above diagram is extrapolation of Fig.3. Here, how the SAN subsystems are connected using IP network is shown. As explained previously SAN supports only Block IO based data flow and doesn’t allow File based IO
operations.
4. NAS (Network Attached Storage or Network Area Storage)
NAS is a file system virtualization storage technology which attaches to a TCP/IP based network using either LAN or WAN connection. This is accessed using specialized file access/file-sharing protocols. NAS supported on I/O requests and this is file based as compared to SAN which is based on Block level access.
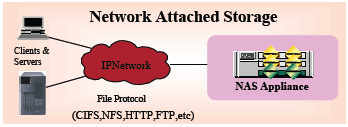
Various protocols are supported in NAS such as NFS (Network File System, NFSv3, NFSv4 etc), SMB (Server message block), CIFS (Common Internet File System) or FTP(file transfer protocol), HTTP. Also, protocols like AFP (Apple filing protocol) which is used for MAC machines is supported on NAS.
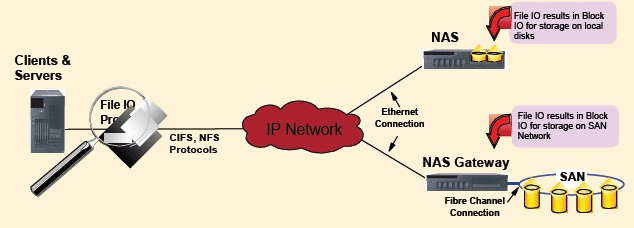
NAS has the following advantages:
- Reliable data operations.
- Built-in features such as good storage efficiency.
- Secure data with authentication.
- Automatic email alerts can be set-up easily.
- Simple data handling along with simple infrastructure manageability.
Related Read: TrueNAS 25.04 Fangtooth is Officially Released!
5. JBOD
This is nothing but Just bunch of Disks(JBOD) connected together. Here no RAID or any such storage technology is used. Just selected group of disks are bundled and connected together as Disk Array. This JBOD is created using multiple independent hard disks and all these disks are recognized as one single HDD by the underlying operating system.
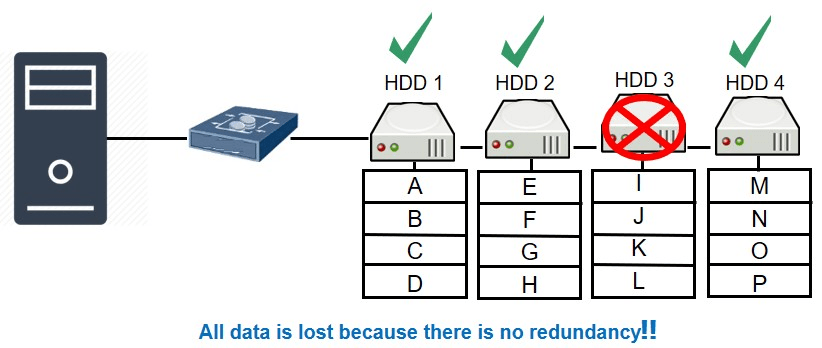
This is again low cost and inefficient model. This will be used where data security and efficiency is not that important. If the data in one of the disks is lost and this will be lost for ever.
Suggested read:
Conclusion
Learning RAID, SAN and NAS concepts will help any storage engineer. Irrespective of progress of Cloud and Hyper-convergence kind of technologies, understanding fundamental storage concepts is very crucial and important. This will also help in gaining knowledge on LVM and Cloud Storage concepts. This article is mainly focused on regularly used and most prominent types of configurations.
If you find any errors and typos in this guide, feel free to let us know. We will amend and update the guide accordingly.
About the author: Shashidhar Soppin is working in Wipro as a Senior Architect having 18+ years of experience in IT industry. He specializes in Unix/Linux system programming, Virtualization, Docker, Cloud, AI-ML, Deep learning & OpenStack areas. He is an Author, blogger and has patents & written papers.
Contact: shashi[dot]soppin[at]gmail[dot]com.