Modern days have seen tremendous growth of applications and these applications started generating lot of data be it from mobile devices or be it from web. As more and more such applications are being built, they needed to deliver the content directly to the user with faster rate irrespective of if they are using Mobile, Tablet, Laptop, Desktop, or any such device. Along with this, handling of larger and larger files became a challenge, this needs lot of Meta data related to the file needs to be stored and accessed when needed. Data storage once looked very easy, became a big challenge now.
Object Storage, which evolved during last few years, helps in solving this need. SDS (Software defined storage) along with Object storage, which were developed keeping in mind about ease of file access, deployment, and management along with saving replica copies address most of the modern day storage challenges.
An Object file is of any type, be it media file, text file, regular file, video file, character file or block file, all these types of files are treated the same. In addition to this, handling of large files in SDS is as easy as it is. Object storage is very powerful because it speaks the language of web using HTTP protocol. Even for archives, file back-ups, digital storage, file sharing and file transactions Object Storage will be a perfect choice.
According to Forbes, each day & every minute following are some of the well-known transactions and how much data they emit:
- Snapchat users share 527,760 photos,
- More than 120 professionals join LinkedIn,
- Users watch 4,146,600 YouTube videos,
- 456,000 tweets are sent on Twitter,
- Instagram users post 46,740 photos.
Above transactions will emit huge amounts of data bytes. These will be in terms of “Zeta Byte” or more. According to IDC, by 2025 approximately 175 Zeta bytes of data to be generated annually. This will be at the rate of 61 percent (compounded annual growth). Just remember that storing this data and management of this data with different types of files is not an easy task.
With the evolvement of Cloud and urgent need of huge data storage, technologies like Object Storage was inevitable. Along the lines of Cloud, Object storage has evolved very fast and many open source communities along with industrial collaboration came forward and contributed to the development of Object Storage. Out of this, following are some of the well-known and heavily used technologies in the domains of Object Storage:
- Swift (In OpenStack).
- Ceph.
- GlusterFS (not pure Object Storage).
- AWS S3 ( Simple Storage Service in Amazon cloud), Azure Blob Storage (from MS), Google Cloud Storage (GCS), IBM Cloud Object Storage, Alibaba OSS, etc,. (All these are cloud based storage providers).
- Dropbox, Google Drive, Cloud Files {Cloud service with individual accounts}.
- Outlook 365 (Email on Cloud).
After talking about Object Storage, one can think why the need of Object Storage and what are the benefits of Object Storage. Following are some of the benefits of Object Storage:
- Object Storage (OS) helps in carrying out data analytics with ease. Since OS is driven by metadata and multiple classification levels, analysis is far greater as compared to normal data storage.
- OS helps in greater scalability aspects. One can keep on adding data without worrying about limits/thresholds.
- Data access, transfer and retrieval will be faster using OS. In OS there is no folder structure and data is categorized for ease of access, this helps in faster access and transfer rate.
- OS definitely helps in reduction of cost. Because of scale-out architecture of implementation, data storage will be less costly affair. All the data is unstructured and any kind of storage requirement can be met with minimal cost and investment.
- OS helps also in resource optimization. Only metadata needs to be stored and this is easily customizable. Because of this nature, there are very fewer drawbacks and limitations of OS as compared to traditional file and block level storage.
- Durability of data. Extent to which data will never be permanently lost or corrupted, in spite of individual component failures.
- Data availability will be high and data manageability will be smoother.
Table of Contents
Brief History of Storage and evolvement of Software defined Storage and Object Storage

CAP Theorem
CAP theorem (also called as “Brewer's theorem”) played a vital role in the development of Object Storage. Eric Brewster (Prof. Computer Division @ Univ. California, Berkeley) framed this problem during 2000. According to this problem, distributed computer systems cannot simultaneously provide the following:
- Consistency: All the clients see the same version of the data at the same time.
- Availability: Whenever read/write to the system happens, it is guaranteed that we will get a response.
- Partition Tolerance: System will work even when the network is not perfect.
For any distributed computer system, any of the above two must be chosen based on the circumstances for any implementation of storage subsystems. This CAP theorem also helped in designing of the Object Storage technology. Because consistency and availability of data play a very crucial role.
Software Defined Storage
We know that there were days where “Mainframe” computers were everywhere. Be it banking sector, creating an animated movie, storing of patient data in hospital, share market, mainframe was the ultimate solution. These mainframe servers worked on with connected hard disc drives, with dedicated storage systems with in-line controllers.
Older generation techno-geeks might have witnessed these main frames, their growth and usage for couple of decades. These were very expensive and maintenance needed skilled resources along with challenges like data migration, back-up etc. Scalability was always an issue in these kind of configurations.
All these challenges and heavy requirement of storage, lead to the development of so-called Software-defined storage (SDS) systems. Both the intelligence and access mechanisms were separated out from the underlying hard disc drives in SDS systems.
Following are the main four components, which define any SDS system:
- Storage routing: This layer acts as a gateway to the storage system. The routers main job is to route storage requests around hardware and networking faults. This router layer scales out with each additional node allowing more and more capacity for data access. Sometimes these routers can be distributed across multiple data centers and geo-locations.
- Storage resilience: The main aim or goal of SDS is the ability to recover from failures thus using software and not the hardware. Various data protection mechanisms or schemes are used to ensure that data is not corrupted or lost at any point of time.
- Physical hardware: This physical hardware is used to store bits of information on disk. The data storage routing systems will be used to route around if node is down.
- Out-of-band controller: This controller can be used to dynamically tune the system to optimize performance, upgrade, maintenance, management of capacity. Faster recoveries are possible in case of hardware failures, which will allow an operator to respond for any operational events.
There are many benefits of using SDS as compared to traditional storage or similar mechanisms. As SDS brings in many advantages, many enterprise level industries, techno-geeks are adopted this on a faster scale. Because of the separation of physical hardware from the software allows configurations as easy job to carry on.
With SDS various sizes of drives with capacity can be used for better performance.
In this article I have described some of the heavily used Object Storage technologies.
Swift (OpenStack)
Swift is an object storage system. OpenStack private cloud supports and maintains swift development, features enhancement, code contribution along with open source community support.
Swift Architecture
Swift has multiple components which interact with each other by providing continuous data availability and data back up.
Following are the various components of Swift:
- Proxy Server: This server is responsible for serving the requests and ties-up all the other components of swift architecture together. This component also handles “Erasure Code” type policies (encoding and decoding object data). This proxy server handles many failures at the basic level. All the objects are streamed from this proxy server without any spooling.
- The Ring: This component is used for mapping of the named entities on disk to their actual physical location. It is must to have one object ring per storage policy and there will be separate rings for all the accounts. The ring maintains this mapping using various aspects like zones, devices, partitions and replicas etc. By default ring is replicated 3 times across the cluster. Ring maintains the mapping and all the partition information is stored here along with location information. In case of failure or disaster kind of situations, ring will take the responsibility on determining which devices can be used and provide uninterrupted data availability. The default number can be changed based on the need and requirement for back up, replica and restore. To maintain the weight, Data is evenly distributed across the capacity of the system. These weights are used for balancing act for distribution of partitions on devices across the cluster.
- Storage Policies: Storage policies will help in distinguishing service levels, features and behaviors of a swift deployment. Each of these policies are configured and are exposed to the client via abstract name. The policy can be of “default with 3x replication” is one such example. Other similar policies can be of using SSD (Solid State devices), Erasure Coding etc. Based on the mapping of the storage policies various measures and actions will take place. To know more about “Erasure code”, refer this link.
- Object Server: This is a simple blob (Binary Large Object) kind of storage server, which can store, retrieve and delete objects stored on local devices. Any object file is stored as binary type of files on the target file systems with metadata in the files attributes. File systems like “ext3” onwards have “xattrs” option by default turned on. Each of the object is stored using a path, which is obtained from combination of its name’s hash and operation timestamp. Always, last write operation gets priority and the same will be used as the latest version.
- Container Server: The primary job of this is to handle listings of all the objects present. It will not care about where and how these objects are stored and what their characteristics are.
- Account Server: This is as same as container server except that this server is responsible for listing of containers rather than objects.
- Replication: To keep the system in consistent state in case of any temporary failures or error conditions like that of n/w outages, disc drive failures etc replication is used. Always replication will compare local data with remote copy to make sure they all contain latest and same version. When the object is removed, replicator makes sure all the relevant data corresponding to that is object is also removed.
- Reconstruction: This is used for Erasure Code based policies and is similar to replicator for replication type of policies.
- Updaters: During failure kind of scenarios or high load, if any update fails, this update will be automatically queued-up on the local file system
Following are some of the advantages of using Swift:
- Because of ring, data distribution, data back-up and retrieval is very fast.
- Data availability is high.
- Data recovery is faster compared to traditional storage mechanisms.
- Using API’s any interface can easily interact with Swift.
- Swift is kind of Plug-n-play storage technology, adopting or configuring it will be easy job.
- Any large sized file can be stored and retried very easily.
The following is the sample architecture diagram of “Swift in OpenStack”:

Ceph (From Redhat)
Ceph is again one of the most popular open source based storage solutions based on the principles of Software Defined Storage and Object storage. Redhat owns and supports Ceph.
Following are some of the well-known features of Ceph:
- Ceph supports massively scalable storage.
- Ceph is cost effective storage solution.
- Supports all types of files including block, object and file.
- Ceph delivers high performance with object storage.
- No vendor locked-in hardware and follows industry open standards.
- Ceph is backward compatible.
- Ceph supports inter-operability and can be tightly integrated with OpenStack’s Swift, Cinder and Manila kind of features.
Ceph is treated as one of the industry standards when it comes to software-defined-storage and it supports hardware which is again industry standard based. As Ceph supports block, object and file types, storage management will be very easy and this helps in automatically managing all the required data. Since Ceph is backward compatible, handling of present block storage resources like iSCSI, NFS (Network File System) can be very easily done.
As mentioned in the features section, Ceph comes equipped with scalability feature in-built. Large data intensive workloads like video delivery networks, Cloud DVR, Network Function Virtualization etc., are handled without any hiccups.
Ceph also supports NVMe(Non-volatile memory express), SSD(Solid State Devices) with performance tiers which are optimized to support the bandwidth, latency and IOPS requirements of high data consuming performance workloads.
More information on what are NVMe and SSD can be found in the reference links given at the end of this guide.
Gluster (& glusterfs)
Gluster is a free and open source based software with scalable network file system. For data-intensive tasks and media streaming kind of work load management, GlusterFS will be a suitable candidate.
Using gluster, multiple disk storage resources from different servers can be aggregated into single global namespace. Which later can be used for storage, even if these servers are hosted in different geo-graphies.
Following are some of the features and advantages of gluster:
- Gluster supports scalability up to several Petabytes.
- Using gluster thousands of clients can be handled.
- Gluster is Posix compatible.
- Gluster uses commodity hardware.
- Gluster provides replication, quotas, geo based replication, snapshotting and BitRot detection.
- Gluster supports optimization for various types of workloads.
It may be re-called that Gluster is not based on pure Object Storage principles, but some of its features and the kind of configuration we do helps in using this as one of the software defined storage mechanisms.
Gluster Architecture
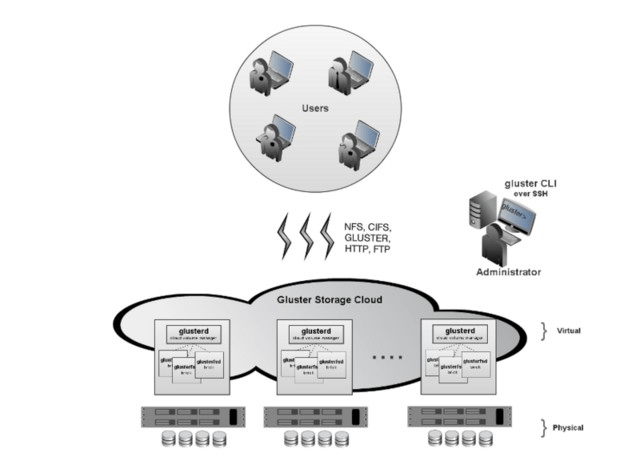
Gluster is heavily used for many domains and industry sectors be it health care, media or similar types where large workloads are being run and dependent on capacity and scalability aspects.
Suggested read:
Conclusion
Learning Object Storage principles, how it evolved and what is Software Defined Storage will help one to understand how storage used in Cloud and IoT kind of environments. Object Storage and Software Defined Storage are becoming de-facto standards for many software industries and enterprises where heavy data usage and workload management is always a challenge. Learning these concepts will help in solving most of the industry challenges in the storage space.
If you find any errors and typos in this guide, feel free to let us know. We will amend and update the guide accordingly.
Contact: shashi.soppin@gmail.com.
References:
- https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/#5972d61d60ba
- https://www.networkworld.com/article/3325397/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html
- https://dzone.com/articles/understanding-the-cap-theorem
- https://docs.openstack.org/swift/latest/overview_architecture.html
- www.swiftstack.com
- https://www.redhat.com/en/technologies/storage/ceph
- https://searchstorage.techtarget.com/definition/SSD-solid-state-drive
- https://en.wikipedia.org/wiki/NVM_Express
- https://docs.gluster.org/en/latest/Administrator%20Guide/GlusterFS%20Introduction/
1 comment
Thank you so much for sharing this informative post with us.