I always backup the configuration files or any old files to somewhere in my hard disk before edit or modify them, so I can restore them from the backup if I accidentally did something wrong. But the problem is I forgot to clean up those files and my hard disk is filled with a lot of duplicate files after a certain period of time. I feel either too lazy to clean the old files or afraid that I may delete an important files. If you're anything like me and overwhelming with multiple copies of same files in different backup directories, you can find and delete duplicate files using the tools given below in Unix-like operating systems.
A word of caution:
Please be careful while deleting duplicate files. If you're not careful, it will lead you to accidental data loss. I advice you to pay extra attention while using these tools.
Table of Contents
Find And Delete Duplicate Files In Linux
For the purpose of this guide, I am going to discuss about three utilities namely,
- Rdfind,
- Fdupes,
- FSlint.
These three utilities are free, open source and works on most Unix-like operating systems.
1. Rdfind
Rdfind, stands for redundant data find, is a free and open source utility to find duplicate files across and/or within directories and sub-directories. It compares files based on their content, not on their file names. Rdfind uses ranking algorithm to classify original and duplicate files. If you have two or more equal files, Rdfind is smart enough to find which is original file, and consider the rest of the files as duplicates. Once it found the duplicates, it will report them to you. You can decide to either delete them or replace them with hard links or symbolic (soft) links.
Installing Rdfind
Rdfind is available in AUR. So, you can install it in Arch-based systems using any AUR helper program like Yay as shown below.
$ yay -S rdfind
On Debian, Ubuntu, Linux Mint:
$ sudo apt-get install rdfind
On Fedora:
$ sudo dnf install rdfind
On RHEL, CentOS:
$ sudo yum install epel-release
$ sudo yum install rdfind
Usage
Once installed, simply run Rdfind command along with the directory path to scan for the duplicate files.
$ rdfind ~/Downloads
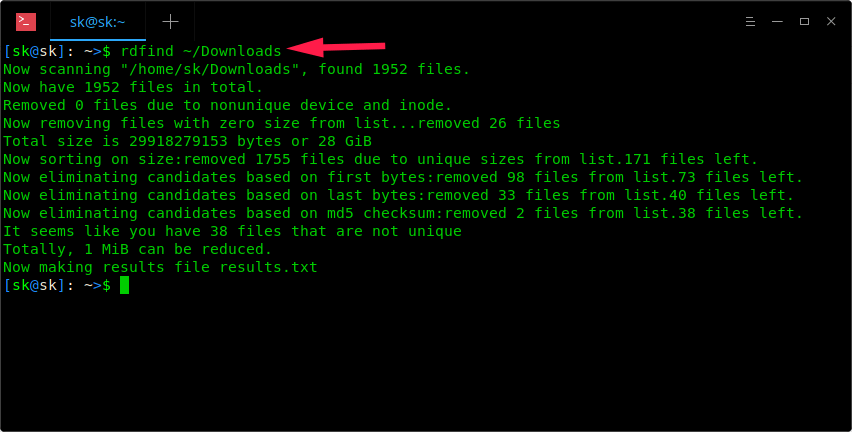
As you see in the above screenshot, Rdfind command will scan ~/Downloads directory and save the results in a file named results.txt in the current working directory. You can view the name of the possible duplicate files in results.txt file.
$ cat results.txt # Automatically generated # duptype id depth size device inode priority name DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex [...] DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf # end of file
By reviewing the results.txt file, you can easily find the duplicates. You can remove the duplicates manually if you want to.
Also, you can -dryrun option to find all duplicates in a given directory without changing anything and output the summary in your Terminal:
$ rdfind -dryrun true ~/Downloads
Once you found the duplicates, you can replace them with either hardlinks or symlinks.
To replace all duplicates with hardlinks, run:
$ rdfind -makehardlinks true ~/Downloads
To replace all duplicates with symlinks/soft links, run:
$ rdfind -makesymlinks true ~/Downloads
You may have some empty files in a directory and want to ignore them. If so, use -ignoreempty option like below.
$ rdfind -ignoreempty true ~/Downloads
If you don't want the old files anymore, just delete duplicate files instead of replacing them with hard or soft links.
To delete all duplicates, simply run:
$ rdfind -deleteduplicates true ~/Downloads
If you do not want to ignore empty files and delete them along with all duplicates, run:
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
For more details, refer the help section:
$ rdfind --help
And, the manual pages:
$ man rdfind
Suggested read:
2. Fdupes
Fdupes is yet another command line utility to identify and remove the duplicate files within specified directories and the sub-directories. It is free, open source utility written in C programming language. Fdupes identifies the duplicates by comparing file sizes, partial MD5 signatures, full MD5 signatures, and finally performing a byte-by-byte comparison for verification.
Similar to Rdfind utility, Fdupes comes with quite handful of options to perform operations, such as:
- Recursively search duplicate files in directories and sub-directories
- Exclude empty files and hidden files from consideration
- Show the size of the duplicates
- Delete duplicates immediately as they encountered
- Exclude files with different owner/group or permission bits as duplicates
- And a lot more.
Installing Fdupes
Fdupes is available in the default repositories of most Linux distributions.
On Arch Linux and its variants like Antergos, Manjaro Linux, install it using Pacman like below.
$ sudo pacman -S fdupes
On Debian, Ubuntu, Linux Mint:
$ sudo apt-get install fdupes
On Fedora:
$ sudo dnf install fdupes
On RHEL, CentOS:
$ sudo yum install epel-release
$ sudo yum install fdupes
Usage
Fdupes usage is pretty simple. Just run the following command to find out the duplicate files in a directory, for example ~/Downloads.
$ fdupes ~/Downloads
Sample output from my system:
/home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf
As you can see, I have a duplicate file in /home/sk/Downloads/ directory. It shows the duplicates from the parent directory only. How to view the duplicates from sub-directories? Just use -r option like below.
$ fdupes -r ~/Downloads
Now you will see the duplicates from /home/sk/Downloads/ directory and its sub-directories as well.
Fdupes can also be able to find duplicates from multiple directories at once.
$ fdupes ~/Downloads ~/Documents/ostechnix
You can even search multiple directories, one recursively like below:
$ fdupes ~/Downloads -r ~/Documents/ostechnix
The above commands searches for duplicates in "~/Downloads" directory and "~/Documents/ostechnix" directory and its sub-directories.
Sometimes, you might want to know the size of the duplicates in a directory. If so, use -S option like below.
$ fdupes -S ~/Downloads 403635 bytes each: /home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf
Similarly, to view the size of the duplicates in parent and child directories, use -Sr option.
We can exclude empty and hidden files from consideration using -n and -A respectively.
$ fdupes -n ~/Downloads
$ fdupes -A ~/Downloads
The first command will exclude zero-length files from consideration and the latter will exclude hidden files from consideration while searching for duplicates in the specified directory.
To summarize duplicate files information, use -m option.
$ fdupes -m ~/Downloads 1 duplicate files (in 1 sets), occupying 403.6 kilobytes
To delete all duplicates, use -d option.
$ fdupes -d ~/Downloads
Sample output:
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf [2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf Set 1 of 1, preserve files [1 - 2, all]:
This command will prompt you for files to preserve and delete all other duplicates. Just enter any number to preserve the corresponding file and delete the remaining files. Pay more attention while using this option. You might delete original files if you're not be careful.
If you want to preserve the first file in each set of duplicates and delete the others without prompting each time, use -dN option (not recommended).
$ fdupes -dN ~/Downloads
To delete duplicates as they are encountered, use -I flag.
$ fdupes -I ~/Downloads
For more details about Fdupes, view the help section and man pages.
$ fdupes --help
$ man fdupes
Also read:
3. FSlint
FSlint is yet another duplicate file finder utility that I use from time to time to get rid of the unnecessary duplicate files and free up the disk space in my Linux system. Unlike the other two utilities, FSlint has both GUI and CLI modes. So, it is more user-friendly tool for newbies. FSlint not just finds the duplicates, but also bad symlinks, bad names, temp files, bad IDS, empty directories, and non stripped binaries etc.
Installing FSlint
FSlint is available in AUR, so you can install it using any AUR helpers.
$ yay -S fslint
On Debian, Ubuntu, Linux Mint:
$ sudo apt-get install fslint
On Fedora:
$ sudo dnf install fslint
On RHEL, CentOS:
$ sudo yum install epel-release
$ sudo yum install fslint
Once it is installed, launch it from menu or application launcher.
This is how FSlint GUI looks like.
As you can see, the interface of FSlint is user-friendly and self-explanatory. In the Search path tab, add the path of the directory you want to scan and click Find button on the lower left corner to find the duplicates. Check the recurse option to recursively search for duplicates in directories and sub-directories. The FSlint will quickly scan the given directory and list out them.
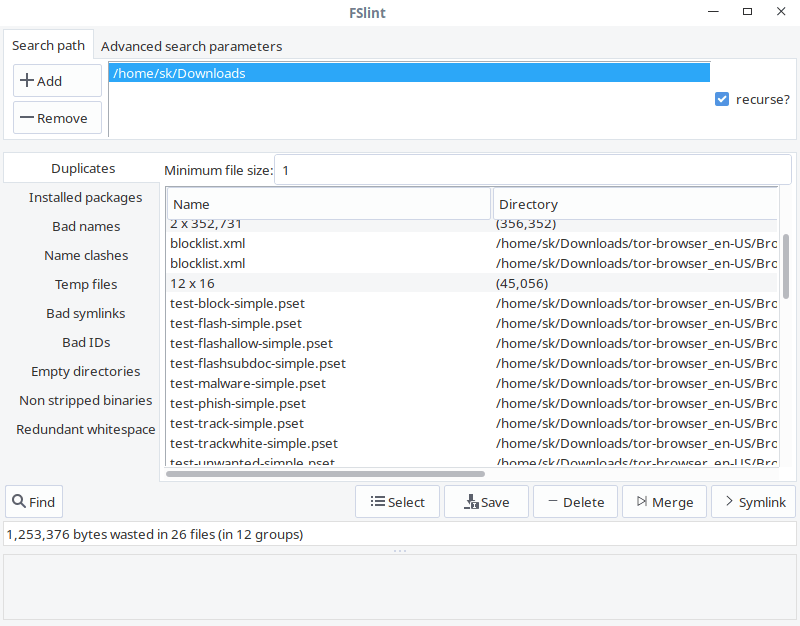
From the list, choose the duplicates you want to clean and select any one of them given actions like Save, Delete, Merge and Symlink.
In the Advanced search parameters tab, you can specify the paths to exclude while searching for duplicates.
FSlint command line options
FSlint provides a collection of the following CLI utilities to find duplicates in your filesystem:
- findup -- find DUPlicate files
- findnl -- find Name Lint (problems with filenames)
- findu8 -- find filenames with invalid utf8 encoding
- findbl -- find Bad Links (various problems with symlinks)
- findsn -- find Same Name (problems with clashing names)
- finded -- find Empty Directories
- findid -- find files with dead user IDs
- findns -- find Non Stripped executables
- findrs -- find Redundant Whitespace in files
- findtf -- find Temporary Files
- findul -- find possibly Unused Libraries
- zipdir -- Reclaim wasted space in ext2 directory entries
All of these utilities are available under /usr/share/fslint/fslint/fslint location.
For example, to find duplicates in a given directory, do:
$ /usr/share/fslint/fslint/findup ~/Downloads/
Similarly, to find empty directories, the command would be:
$ /usr/share/fslint/fslint/finded ~/Downloads/
To get more details on each utility, for example findup, run:
$ /usr/share/fslint/fslint/findup --help
For more details about FSlint, refer the help section and man pages.
$ /usr/share/fslint/fslint/fslint --help
$ man fslint
Conclusion
You know now about three tools to find and delete unwanted duplicate files in Linux. Among these three tools, I often use Rdfind. It doesn't mean that the other two utilities are not efficient, but I am just happy with Rdfind so far. Well, it's your turn. Which is your favorite tool and why? Let us know them in the comment section below.
Resources:
- Rdfind Website
- Rdfind GitHub Repository
- Fdupes GitHub Repository
- FSlint Website
- FSlint GitHub Repository
Thanks for stopping by!
Help us to help you:
- Subscribe to our Email Newsletter : Sign Up Now
- Support OSTechNix : Donate Via PayPal
- Download free E-Books and Videos : OSTechNix on TradePub
- Connect with us: Reddit | Facebook | Twitter | LinkedIn | RSS feeds
Have a Good day!!
6 comments
dupeguru imho is easier.
Thanks for reminding me. I completely forgot about this tool. I will add it in the list soon.
Thank you for sharing this.
What I’m looking for is a tool to identify whole directories which are duplicate (recursive). So it would match two folders if their contents are the same. This way it would be a lot less work (compared to removing each individual file by hand). Do you know of such a tool? Or are any of the ones you listed capable of this feature?
Thanks!
Have you tried “diff” command? I guess it is what you’re looking for. diff command comes pre-installed on most Linux distros.
If you want GUI for directory comparison, maybe look at “FreeFileSync.” Not sure your exact need, but it came to mind first. It was in the repository of one distro I use, but not others, but it is opensource and you can download and compile. Other GUI-driven solutions I also use are Meld and Kdiff3 but I tend to use them for single-layer directory comparison (not recursive searching, though they can do that) and use FreeFileSync for looking at whole “tree.”
The above **ARE** GUI tools. I do like CLI and use it quite a bit, but with large directories with multiple subdirectories on my personal system/ home network, I like the graphical approach. If CLI is your thing, “diff” as per sk’s comment, is good too. Good luck!
OK. Good job! Thanks.